How Whitefox.cloud Embedded Claude Across Padua Solutions:Financial Advice Workflows, Software Delivery, and AI-Powered Products
A Whitefox.cloud case study on enterprise Claude adoption in regulated fintech
A Whitefox.cloud case study on enterprise Claude adoption in regulated fintech

Matthew Esler
Co-founder & CEO of Padua Solutions
“Finding a reliable and results-driven technology partner is exceptionally challenging. Amir, in his capacity as a fractional CTO, and the Whitefox.cloud team have consistently demonstrated speed, precision, and technical excellence. They have delivered iterative, cost-effective, and high-value software solutions aligned with our commercial objectives. In a highly regulated fintech environment, their innovative and compliance-aware execution of key technology initiatives has been exemplary. I can confidently endorse their innovation, capabilities, and partnership approach.“
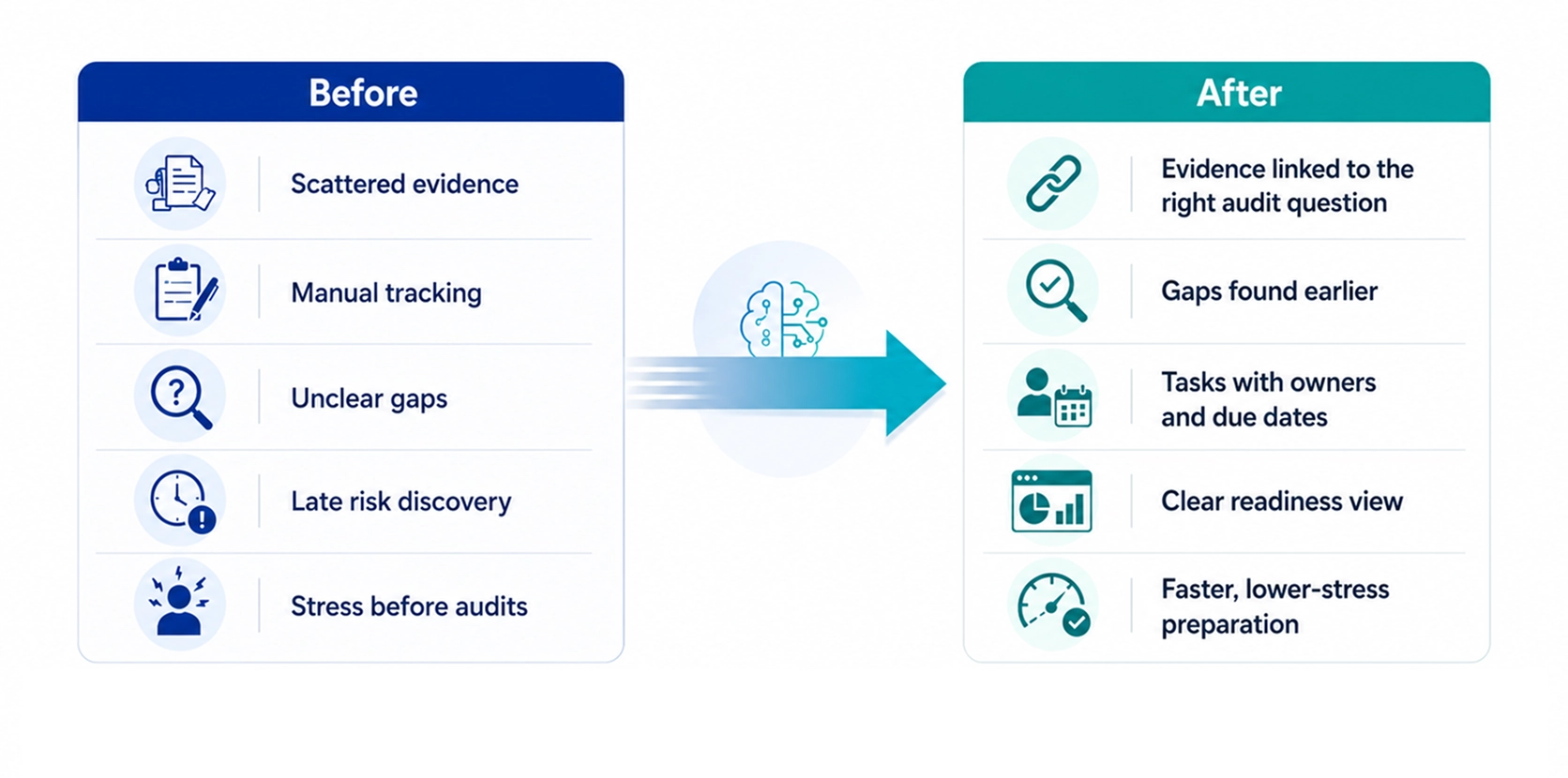
Overview
Executive Summary
Padua Solutions operates in one of the most highly regulated corners of Australian financial services: paraplanning and Statement of Advice (SOA) production for licensees and advisers. When Whitefox.cloud came on board as Padua's fractional CTO and engineering partner, the goal was not "add some AI". The goal was to embed Claude into the daily operating model of the business — across financial experts, software delivery, and AI-powered products — without compromising the compliance posture that the business depends on.
This case study describes how Whitefox.cloud helped Padua adopt Claude across three layers:
Claude as a daily thinking partner for paraplanners, technical services, and product subject matter experts
Claude Code as the backbone of a holistic, auditable software delivery workflow used by engineers, designers, and tech leads
Claude models embedded in Padua products for advice quality assurance, regulatory checks, content generation, and client-engagement workflows — running on Amazon Bedrock with explicit guardrails
The result was a more systematic way to apply financial expertise, engineering discipline, and AI capability together.
Context
Padua's Business Context
Padua combines expert advice teams and smart software to deliver higher-quality, better-value financial advice with faster turnaround times. Their solution sits at the intersection of advice software, paraplanning services, and compliance review for the Australian financial advice market.
The work is document-heavy, judgment-heavy, and regulator-facing:
Paraplanners produce Statements of Advice that have to satisfy the ASIC regulations.
QA (Quality Assurance) Managers review advice documents as needed.
Customer success teams support advisers by progressing engagements after the discovery through to a compliant SOA.
Engineers maintain a multi-product platform spanning fact find, advice generation, financial research data, and adviser-facing portals.
Financial advice must be delivered clearly, accurately, and responsibly so end customers can make informed decisions with confidence.
The challenge was never "could AI help here". The challenge was making AI safe, repeatable, and useful inside real workflows — for both technical and non-technical teams — without becoming a compliance liability.
That is the problem Whitefox.cloud was brought in to solve.
Challenge
The Adoption Challenge
Financial advice work is document-heavy and compliance-sensitive. Most outputs are auditable.
Paraplanners and QA managers need speed, but cannot sacrifice judgment or regulatory quality.
Software teams need to move faster without producing low-quality AI-generated code that turns into long-term tech debt.
Product teams want AI capability, but with controls, auditability, and clear safety boundaries — particularly around advice content.
AI adoption fails when it is left as optional experimentation. It only sticks when it is designed into workflows, with an opinion about how it should and shouldn’t be used.
Here’s how these constraints shaped the adoption model.
Approach
The Three-Layer Adoption Model
Whitefox.cloud structured Padua's Claude adoption across three layers, each with a different audience and a different governance posture.
The point of treating these as separate layers is governance: the rules of use are different for "a paraplanner improving a draft" versus "an engineer generating production code" versus "a Claude model embedded in a product that touches client data". Each layer needs its own approved patterns, review steps, and audit trail.
Layer | Audience | Tool | Purpose |
|---|---|---|---|
1 | Internal Financial experts (paraplanners, technical services, product SMEs) | Claude | A daily thinking partner for advice content drafting without exposing any sensitive client information. |
2 | Engineers, designers, tech leads | Claude Code | A holistic software delivery workflow automation with planning, review, and audit built in |
3 | Customer facing | Claude models on Amazon Bedrock | Products embedded with AI-powered advice QA, content generation, meeting capture, and engagement workflows |
Workflows
Layer 1 — Claude for Financial Experts
The first layer is the easiest one to underestimate. Most Claude rollouts focus on engineers; the bigger productivity unlock at Padua came from putting Claude in front of paraplanners, QA managers, technical services, and product SMEs as a daily tool.
Who is using it
Paraplanners drafting advice content without exposing any sensitive client information
Technical Services authoring and maintaining the strategy text library that drives advice generation
Product SMEs translating regulatory requirements into product specifications
Operations and customer success teams preparing structured outputs from messy inputs
What they use it for
Paraplanning support
Claude has become a thinking partner for paraplanners working through advice preparation: structuring advice notes, summarising long client documents, identifying missing information, drafting strategy explanations, comparing recommendation logic, preparing clearer SOA sections, and reducing repetitive writing effort.
Claude assists with drafting, reasoning, checking, and summarising. Final advice responsibility remains with qualified human experts. This is not a hedge — it is a core design principle that shapes everything from prompt patterns to review steps.
Financial content generation with safety guards
Claude is used for first-pass drafting of client education material, strategy summaries, advice explainer content, internal knowledge articles, review notes, and reusable templates. The safety guards are explicit:
Approved prompt patterns shared across the team
Human review before any client-facing use
Restricted source material — only inputs sources the business already trusts
Style and compliance checks applied to outputs
Versioning and traceability for anything that ends up in a template
A clean separation between draft generation and final approval
People adopted the tools because they had confidence in how they should be used, not because someone told them they had to.
Engineering
Layer 2 — Claude Code for Software Engineers, Designers, and Tech Leads
The second layer is where Padua's engineering practices changed most visibly. Whitefox.cloud was brought in to uplift engineering practices, and Claude Code became the backbone of how that uplift was operationalised.
This was not "developers can use AI if they want to". It was a designed workflow with a shared .claude/ folder committed to every repository — including team commands, sub-agents, and Claude Skills — so that everyone on the team experiences the same opinionated process, regardless of seniority.
Why this matters for regulated environments
Plan-first, code-second. Claude is most valuable when it is used before coding starts. The plan document forces explicit hard limitations and sub-plan structure, which catches the kind of vague tickets and hidden assumptions that normally cause expensive rework.
Every commit is deployable to production. Tests and implementation are committed together. Feature flags are used to maintain deployability across sub-plans and are removed in the final sub-plan. There are no half-finished commits sitting on a branch.
The developer owns git. Claude never commits, pushes, or creates MRs by itself. The exact commands are printed for the developer to run, but the human is always the one taking the action that touches version control.
Severity-tiered findings with mandatory back-and-forth. Critical findings cannot be auto-fixed; the developer has to engage with them. This is deliberately designed to keep judgment in the loop.
Plan and review documents are part of the audit trail. They merge with the code. A reviewer reading the MR six months later can see what was planned, what changed, and why.
The skills directory inside .claude/ is a small but important detail. Team coding rules and API guideline standards live there as Claude Skills, which means the same rules are applied consistently across the team without anyone having to remember to reference them.
Claude Code as a designer-engineer collaboration tool
Claude Code is not just for backend engineers. Padua's product designers use Figma Make alongside Claude to prototype UI flows in real components rather than static screens. The team has been moving toward a hosted Storybook component library that exposes its own MCP endpoint, so that Claude Chat, Claude Code, and Claude Desktop can all see the canonical component library when generating UI. This shortens the loop between design intent and shippable code, and it gives engineers and designers a shared source of truth.
A second AI Code Review pipeline in CI/CD
Beyond developer-driven Claude Code review, Padua also runs an automated AI Code Review pipeline in GitLab CI/CD on every non-draft MR. Three specialised review agents run in parallel via Amazon Bedrock — code quality, security, and API compliance — using a mixed-model strategy: Opus for security (best reasoning for vulnerability detection), Sonnet for the pattern-based checks. The pipeline is advisory, not blocking: Bedrock errors, throttling, or bad responses degrade gracefully without stopping merges.
The security posture matters. Sensitive files (.env, private keys, credentials) are filtered before any diff reaches Bedrock. A secret pattern scanner aborts the review if anything looks like a credential. Output is scanned again on the way back to strip residual secrets and any GitLab quick-action commands. Bedrock was selected partly because it supports enterprise data-protection requirements appropriate for regulated environments.
This is the kind of Claude API integration for code review implementation that organisations in regulated industries actually need: model-agnostic via Bedrock, authenticated via runner instance role rather than long-lived credentials, with cost guardrails (~$1 per pull request review) and structured findings that are easy to act on.
Leadership
Layer 2.5 — Tech Lead Workflows: Architecture, Review, and Standards
A common failure mode of AI adoption in engineering is that it creates more code, faster, with no corresponding uplift in review or architectural thinking. Whitefox.cloud treated this as a first-class risk and built tech lead workflows specifically around it.
Code review
Tech leads use Claude to review pull requests at depth — identifying risky changes, checking test coverage, spotting hidden coupling, challenging unnecessary complexity, comparing implementation against requirements, and improving readability. Claude helps tech leads review more deeply, not less responsibly. Padua's engineering practice already requires every code change to be reviewed by a Team Lead or Principal Engineer before it is merged; Claude makes that review more thorough rather than skipping it.
Architecture and ADRs
Padua maintains an Architecture Decision Record (ADR) practice: any significant architectural choice is captured in a written ADR, reviewed by the Team Lead, Principal Engineers, and at least one of the engineering leadership team. Claude is used heavily during ADR drafting — exploring options, comparing trade-offs, drafting the document, reviewing data flows, threat modelling, identifying operational risks, and stress-testing assumptions before any code is written.
Examples from the actual ADR backlog include decisions on:
Storage patterns for structured and unstructured data, with explicit pros, cons, and proof-of-concept results
Data modeling with full audit and AI-prefill support
Access permission models for the new Identity and Access Management service
Component library decisions for a shared Storybook + MCP architecture
The pattern is consistent: Claude helps the team think harder earlier, when changing direction is still cheap.
Engineering standards
Whitefox.cloud helped codify a set of engineering principles that Padua's teams now treat as the foundation of how they work: make small changes often, take ownership end-to-end, first unblock others, design secure systems with secure defaults, build extensible systems for the requirements you actually have, don't optimise prematurely, build systems to be read, and treat technical debt as a deliberate decision that needs a repayment plan.
These principles are not posters on a wall. They are reinforced inside the Claude Code workflow — the security-scanner sub-agent, the plan-drift-checker, the API compliance checker — so that the standards apply consistently regardless of who wrote the code or what time of day it was.
Product
Layer 3 — Claude Models Embedded in Padua's AI-Powered Products
The third layer is where AI adoption stops being an internal productivity story and becomes a product story. Whitefox.cloud worked with Padua's product teams to embed Claude models — primarily via Amazon Bedrock — into the products themselves, with explicit guardrails for a regulated environment.
Three product-level use cases stand out.
1. Advice quality assurance with Claude Models on Bedrock
Padua's automated SOA auditing capability uses Claude models on Amazon Bedrock to review advice documents against a structured quality checklist across multiple sections. The system is designed for a real production load, not a demo, which means it had to confront real economics.
The architectural choices reflect that:
Visual-mode analysis on PDF pages, not just extracted text. This lets the model see actual page layouts, charts, and visual tables — important because advice documents are visually structured, not pure prose.
Hybrid prompt granularity. Section-wise analysis for simple sections, item-wise analysis for complex sections. The result costs roughly 50% less per analysis at production quality compared to naive item-wise analysis on visual mode.
Model tiering. Cheaper models (Haiku) for simple checklist items, more capable models (Sonnet, Opus where reasoning matters most) for complex ones.
Prompt caching where the API supports it. A 90% discount on cached input tokens is the difference between viable and not, and Whitefox.cloud measured exactly which paths support caching and which don't.
Domain-grounded outputs. AI generates QA scores and issue lists. Interpretation against real compliance standards remains with the Padua audit team.
The framing inside the product is the same as the framing inside the QA team: AI does not replace advice QA. It gives reviewers a better first pass and a sharper issue list.
For anyone evaluating Claude API for compliance automation, this is what production-grade looks like in a regulated setting: explicit cost engineering, clear quality boundaries, human-in-the-loop review, and an audit trail back to the source document.
2. AI-assisted advice generation
A long-standing pain point in advice production is that real-world advice is rarely a single action. A typical pre-retirement scenario involves rolling super to a new fund, contributing additional capital, and then commencing a pension — three connected steps where only the final state matters to the client.
Without AI, the system produced a product comparison for every step, requiring paraplanners to manually edit the final document by hand. With AI, the work for the paraplanner shifts mostly from doing to checking: use the AI to draft, add client specific data, confirm it is correct, and publish.
This is a clean example of Claude API for AI agents at the boundary between domain expertise and generative capability: the domain experts define the canonical strategy vocabulary once; the AI handles the reasoning across arbitrary sequences without the engineering team having to write a new template every time a new combination appears.
3. AI Agent for Meetings — Claude-powered meeting intelligence for adviser engagement
AI Agent for Meetings is Padua's strategic AI initiative for the adviser-client engagement layer of the advice journey. First release targets a specific high-impact problem: advisers and internal teams spend disproportionate time on manual meeting documentation, which creates capacity constraints, handoff gaps, and incomplete client records.
The first release uses a combination of Amazon Transcribe for speech-to-text, and Amazon Bedrock (with Claude models) for structured output generation. It supports recording from Teams, Zoom, and Google Meet; from browser sessions on laptop or mobile; or from pre-recorded transcript uploads. From those inputs it produces structured file notes for all meetings — each with a different field schema based on what the regulator and the licensee require.
The design principles are explicitly shaped by ASIC governance:
A raw transcript is not a compliant file note. The AI Agent outputs are structured as file notes that are aligned with relevant Australian financial advice obligations and internal licensee requirements.
All AI-generated file notes require explicit adviser approval before finalisation.
The audit log captures the full lifecycle from raw transcript to approved record.
Outputs must be grounded in the specific content of the recorded interaction — generic, templated language that could apply to any client is treated as a compliance liability, not an asset.
For customers building Claude API for regulated workflows, AI Agent for Meetings is a useful reference architecture: capture, transcribe, generate structured output, require human approval, log everything, and let the structure of the output itself enforce regulatory completeness.
Insights
Operational Insight Through Image Analysis: Measuring Effort
A specific pattern Whitefox.cloud helped establish at Padua is using Claude's multimodal capabilities with governance controls to analyse advice document images and screenshots — not for surveillance, but to give operations leaders better visibility into where complex effort actually goes.
Padua's existing approach used a complexity-weighted productivity score and a Difficulty Weighting class to reflect that not all advice documents are equal. A simple risk-only SOA does not require the same effort as a multi-strategy retirement plan with insurance, super rollovers, and aged care components. The historical scoring relied on heuristics over advice metadata; Claude's vision capability lets the team look at the actual artefact — document density, layout complexity, embedded tables, manual annotations, and the structural signals that reflect real complexity.
The intent is operational, not punitive:
Better visibility into where complex work is consuming time
Better workload planning across advice generation and customer success managers
Better separation between "this took a long time because it was complex" and "this took a long time because of friction we can remove"
The governance posture is explicit: aggregate insights are used over individual scoring, humans remain responsible for performance interpretation, staff are told what is being measured and why, client data is protected, and AI estimates are never turned into unquestioned productivity scores. The goal is to make the operational picture clearer, not to make individuals more measured.
Governance
Governance, Safety, and Change Management
Padua operates in financial advice. Governance is not a final chapter — it is the precondition for adoption.
The governance framework Whitefox.cloud helped Padua implement covers, at minimum:
Approved AI use cases per role. Paraplanners, QA managers, technical services, engineers, designers, and tech leads each have a documented set of approved patterns.
Data handling rules. What can be sent to Claude web vs. Claude Code vs. an API call into Bedrock, and what cannot.
Human review requirements. Every client-facing or compliance-relevant AI output is reviewed before use.
Prompt libraries and approved patterns. Shared so that good practice is the default, not the exception.
Model usage standards. Including model tiering, cost ceilings, and documented choices about which model is used for which task.
Output validation and escalation paths. For high-risk advice areas in particular.
Audit trails. Plan documents and review documents merge with code; AI-generated file notes have full lifecycle logging; AI outputs are traceable back to source.
Role-based access in production AI products and in supporting tooling.
Training and onboarding so that adoption scales beyond the early adopters.
A clear separation between assistive AI and final professional judgment. This shows up in every layer.
This is the part of an AI rollout that is invisible from the outside but is decisive in whether it stays alive after the launch announcement.
Adoption
Adoption Across Roles
Role | Claude usage | Main benefit |
|---|---|---|
Paraplanners | Drafting, summarising, checking advice logic | Faster preparation and clearer outputs |
QA managers | Review support, issue detection, audit notes | More consistent review process |
Technical services | Advice text authoring, Claude-assisted strategy component generation | Throughput across the strategy library, lower expertise threshold for component work |
Software engineers | Plan-first development, TDD, automated review, refactoring | Faster delivery with better planning |
Designers | UX flows, design-to-code via Figma Make + Storybook MCP | Clearer product thinking, less translation loss |
Tech leads | Code review, architecture, ADRs | Better quality control and decision-making |
Product teams | Embedded Claude models in advice QA, content tools, meeting capture | Scalable product capability |
Operations leaders | Effort and complexity analysis, capacity planning | Better operational insight |
Results
Outcomes and Impact
Whitefox.cloud is careful with numbers in regulated environments — most of Padua's adoption gains are operational rather than benchmarked — but the patterns are clear.
Productivity. Paraplanners shifted from "doing and fixing" to "reading and approving" on SOAs. Engineers shifted from large, hard-to-review MRs to small, planned sub-plans with automated review. Customer success handovers and meeting documentation moved from hand-written effort to AI-drafted, human-approved outputs.
Quality. Advice review became more consistent across QA managers because the AI first pass surfaces the same kinds of issues every time. Code review went deeper, not lighter, because tech leads use Claude to dig into the parts of a change they would normally skim. Architecture decisions are written down, reviewed, and explicit because Claude removes the friction of drafting an ADR.
Adoption. Claude is used by both business and technical teams. Resistance dropped because the use cases were practical. Habits formed around prompt patterns, review steps, and escalation paths.
Product innovation. AI moved from internal productivity into product capability: advice QA, regulatory checks, content generation, modeling, meeting intelligence, and operational effort measurement all became product opportunities or first-class capabilities.
Cost engineering. SOA quality analysis costs dropped significantly per run on visual item-wise to roughly half per run on visual hybrid with model tiering — and to around 10% per run for test pipelines using text-mode invoke with prompt caching. These are the kinds of numbers organisations notice when their AI bill arrives.
Learnings
Lessons Learned
A few things became clear during this programme that are worth pulling out for any team starting a similar Claude adoption:
AI adoption works best when tied to real workflows, not generic training sessions. The biggest unlock came from putting Claude into specific paraplanner, QA, and engineering workflows with approved patterns — not from giving everyone access and hoping.
Financial experts need practical examples, not abstract AI demos. Show a paraplanner what Claude does to a real advice section, and they get it. A general "intro to AI" session usually fails to land.
Engineers get the most value when AI is used for planning, review, and testing — not just code generation. The plan-first, review-per-sub-plan workflow produces more durable gains than autocomplete-style use.
Governance has to be designed early, especially in regulated environments. The governance posture is the reason adoption stays alive after the launch.
AI should expose uncertainty and risks, not hide them. Severity-tiered review findings, mandatory back-and-forth on critical issues, and explicit human approval steps make this real.
The best results came from pairing domain experts with technical teams. The QA checklist, the AI Agent for Meetings file note schema, and the advice QA cost-optimisation plan all came from cross-functional work.
Claude Skills are most powerful when they encode standards your team already cares about. Coding rules, API guidelines, commit conventions, security patterns — putting these into a
.claude/skills/directory that ships with the repo is the difference between a "nice-to-have" and a workflow that scales.
Summary
Conclusion
Padua's AI adoption succeeded because Claude was used across the full operating model: expert workflows, software delivery, technical leadership, and AI-enabled products. The result was not just faster work. It was a more systematic way to apply financial expertise, engineering discipline, and AI capability together — inside one of the most regulated corners of Australian financial services.
For businesses in regulated industries looking for a partner who can actually help them adopt Claude — and for organisations that have just bought Claude and now have to make it work — the model is the same one Whitefox.cloud brought to Padua: define the layers, define the governance, encode your standards as Claude Skills, design the workflows, and stay accountable for the outcome.
If you want to understand how this transformation started at the workflow level — including how inefficiencies inside financial advice documents were measured and redesigned — explore our AI workflow automation in financial services case study.
Company
About Whitefox.cloud
Whitefox.cloud is a software and AI company headquartered in Australia, with a global delivery team. We help companies in regulated industries — financial services, healthcare, fintech, and beyond — adopt Claude across their operating model. Our work spans:
Fractional CTO and Principal Architect engagements with hands-on delivery (not advisory-only)
Claude API development and Claude API integration services for production AI products
Claude skills implementation and custom Claude skills development for engineering and operations teams
Claude Code skills consulting for code review automation and engineering productivity
Claude API consulting services for regulated industries — financial services, healthcare, compliance workflows
AI product development on Amazon Bedrock and the Anthropic API, with explicit cost optimisation and governance design
If you have just bought Claude and you are working out how to get real adoption inside a regulated business, we would like to talk.