
Streamlining Healthcare Data Integration: Leveraging FHIR, AI Mapping, and Legacy Systems


Hesam Rezayi, Azin Mirbostani
.10 min read
.27 May, 2024
Software Engineer, Software Engineer
.10 min read
.27 May, 2024
1. AI Mapper User Interaction - Healthcare Data Integration
The first workflow involves creating a JSON file that maps data between the legacy system and FHIR standards. This process shows how users interact with the AI Mapper to transform and map data accurately, ensuring seamless integration.

Components and Workflow (User Interaction)
User Upload:
Users upload JSON files of specific resources to the Mapper Dashboard.
This step allows users to provide real-world data samples that need to be transformed into FHIR-compliant formats.
Users can upload various types of healthcare data, such as patient records, medical histories, and lab results.
The dashboard is designed to be intuitive, enabling users to easily drag and drop files or select them from their devices.
Secure upload mechanisms ensure that sensitive healthcare data is protected during the transfer process.
Data Processing:
The AI Mapper references the FHIR Resource Schema and employs AI prompts to process and map the uploaded JSON data.
This involves parsing the uploaded JSON and identifying the structure and key-value pairs within the data.
The AI Mapper uses machine learning models trained on vast datasets to understand and predict the correct mapping to FHIR standards.
During this process, the AI Mapper validates the data, checking for completeness and consistency with FHIR requirements.
The goal is to accurately transform the legacy data into a standardized FHIR format, ready for use in modern healthcare systems.
User Review and Feedback:
The Mapper Dashboard displays the mapped results for user review, allowing users to provide feedback and corrections.
Users can see a side-by-side comparison of the original and mapped data, making it easier to identify any discrepancies.
The dashboard provides tools for users to annotate and correct the mapped data, ensuring high accuracy in the transformation.
Feedback from users is crucial as it helps identify edge cases and data anomalies that the AI might have missed.
This interactive review process ensures that the final data output meets the high standards required for healthcare interoperability.
Continuous Improvement:
This feedback is incorporated into the AI Mapper, improving future data mappings and ensuring more accurate transformations over time.
The AI Mapper learns from user inputs, adjusting its algorithms and models to better handle similar data in the future.
Continuous learning allows the system to evolve, becoming more precise and efficient with each iteration.
Regular updates to the AI Mapper incorporate the latest feedback, ensuring it stays current with changing data standards and user needs.
This iterative process of improvement enhances the overall reliability and accuracy of the data transformation process, benefiting all users.
How the AI Mapper Works for Data Integration in Healthcare
Data Ingestion:
The AI Mapper starts by ingesting data from various sources, including legacy databases and user uploads.
It supports multiple data formats and schemas, making it versatile for different healthcare data environments.
During ingestion, the system scans and identifies the structure of the incoming data, preparing it for transformation.
This step involves collecting data from disparate sources, ensuring that all relevant information is captured.
Secure data handling protocols are in place to protect sensitive healthcare information throughout the ingestion process.
Schema Mapping:
Using predefined FHIR Resource Schemas, the AI Mapper maps incoming data to the appropriate FHIR resources.
This involves identifying equivalent fields and structures between the old schema and the FHIR standard.
The AI Mapper leverages a comprehensive library of FHIR resources, ensuring accurate and consistent mapping.
It employs sophisticated algorithms to handle complex mappings, such as nested structures and multiple references.
The goal is to create a seamless transformation that aligns legacy data with modern FHIR specifications, enhancing interoperability.
AI and Machine Learning:
The core of the AI Mapper utilizes machine learning algorithms to learn from data patterns and user feedback.
It continuously improves its mapping accuracy by incorporating user corrections and feedback into its learning process.
The system uses supervised learning techniques, training on annotated datasets to enhance its predictive capabilities.
By recognizing patterns and anomalies in the data, the AI Mapper can adapt to various data types and structures.
This adaptive learning process ensures that the AI Mapper becomes more efficient and accurate over time, reducing the need for manual intervention.
Data Transformation:
Once the mapping is defined, the AI Mapper transforms the data into FHIR-compliant JSON.
This process includes data cleaning, normalization, and validation to ensure that the output is accurate and compliant with FHIR standards.
Data cleaning involves removing inconsistencies and correcting errors to produce high-quality data.
Normalization ensures that data is standardized, making it compatible with other datasets and systems.
Validation checks are performed to confirm that the transformed data adheres to FHIR specifications, maintaining data integrity.
2. Secondary Database for FHIR Integration
The second workflow focuses on integrating data from legacy databases into a FHIR server, both as a one-time batch process and as an ongoing synchronization.

Components and Workflow (Secondary Database)
Offline One-Time Data Transformation
Data Extraction from Legacy Database:
Data is initially fetched from the legacy database and sent to a Mapper Proxy.
This step involves querying the legacy systems to retrieve all relevant historical data that needs to be transformed.
The data extraction process is carefully managed to ensure that no critical information is missed.
Typically, this involves exporting data in its native format, which might be complex and varied depending on the legacy system.
Extracted data is then securely transferred to the Mapper Proxy for the next stage.
Data Transformation:
The AI Mapper processes and transforms this data into a FHIR-compliant JSON format.
During this stage, the AI Mapper analyzes the legacy data structure and maps it to the appropriate FHIR resources.
Data Loading:
The transformed data is then loaded into the FHIR server, ensuring that the new system is populated with accurate and relevant historical data.
This step involves importing the FHIR-compliant JSON data into the FHIR server’s database.
The loading process must ensure data integrity and consistency, avoiding duplication or loss of information.
Robust error-checking mechanisms are in place to validate the data before it is fully integrated.
Once loaded, the FHIR server can provide a comprehensive historical record, facilitating better patient care and data analytics.
Synchronization Scenario
Real-Time Data Changes:
Any changes occurring in the legacy database are captured and processed in real time.
This ensures that any new data or updates in the legacy system are immediately reflected in the FHIR server.
Real-time data synchronization prevents discrepancies between the two systems, maintaining data accuracy.
This process involves continuously monitoring the legacy database for any modifications, additions, or deletions.
Quick processing of these changes is essential to ensure that the FHIR server remains current and reliable.
Streaming Layer:
A robust streaming infrastructure (comprising Debezium, Kafka, and Zookeeper) manages these changes and forwards them to the Mapper Proxy.
Debezium captures database changes in real time, acting as a connector between the legacy system and Kafka.
Kafka handles the data stream, providing a scalable and fault-tolerant system to process data changes.
Zookeeper manages the distributed components, ensuring high availability and coordination within the system.
This streaming setup allows for efficient and scalable handling of real-time data changes, supporting large-scale deployments.
Data Transformation and Loading:
The AI Mapper transforms the streaming data into FHIR-compliant JSON.
This transformed data is then promptly updated in the FHIR server, maintaining synchronization between the legacy and FHIR databases.
3. Proxy for FHIR Integration
The third workflow demonstrates the interaction between user devices and the FHIR server via a proxy system, which facilitates seamless data requests and transformations.

Components and Workflow (Proxy Integration)
User Interaction:
Users access healthcare data by sending requests to the FHIR Proxy.
User requests might include viewing patient records, updating medical information, or retrieving specific health data.
Security protocols ensure that only authorized users can access sensitive health information, protecting patient privacy.
FHIR Proxy:
The proxy forwards these requests to the legacy system, where the required data is processed and returned in a legacy format.
Acting as an intermediary, the FHIR Proxy handles the complexities of interacting with older systems.
It translates modern requests into a format that the legacy system can understand, facilitating seamless communication.
This layer abstracts the underlying legacy infrastructure, providing a simplified interface for modern applications.
Efficient handling of requests ensures minimal latency, providing users with quick access to necessary data.
Data Transformation:
The Mapper Proxy receives this data and leverages the AI Mapper to transform it into FHIR-compliant JSON.
This transformation process includes mapping legacy data fields to FHIR standards, ensuring compatibility.
AI algorithms analyze the data, identifying patterns and structures to accurately map the information.
The AI Mapper also performs data validation, checking for any inconsistencies or errors in the incoming data.
By converting the data to FHIR-compliant JSON, it ensures interoperability with modern healthcare applications.
Response Delivery:
The transformed data is then sent back to the FHIR Proxy, which delivers it to the user in a standardized format.
This step ensures that users receive data in a consistent and readable format, regardless of the original data source.
The FHIR Proxy handles the final formatting, preparing the data for display on various devices.
It also manages any necessary security and privacy checks before delivering the data to the end user.
Users receive timely, accurate, and standardized data, enhancing their ability to make informed healthcare decisions.
Conclusion
Integrating legacy healthcare systems with modern FHIR servers is a complex yet vital task for achieving data interoperability. By leveraging advanced tools such as AI mapping and robust synchronization mechanisms, healthcare organizations can ensure seamless data transformation and real-time synchronization. This not only enhances the accuracy and efficiency of healthcare data management but also paves the way for improved patient care and operational efficiency.
These workflows exemplify how technology can bridge the gap between outdated and modern systems, enabling a more connected and efficient healthcare ecosystem. As we continue to innovate and refine these processes, the future of healthcare data integration looks increasingly promising.
Simplify Your FHIR Integration with Our Free Tools
FHIR Data Converter
Effortlessly transform and map custom data to FHIR standard formats.
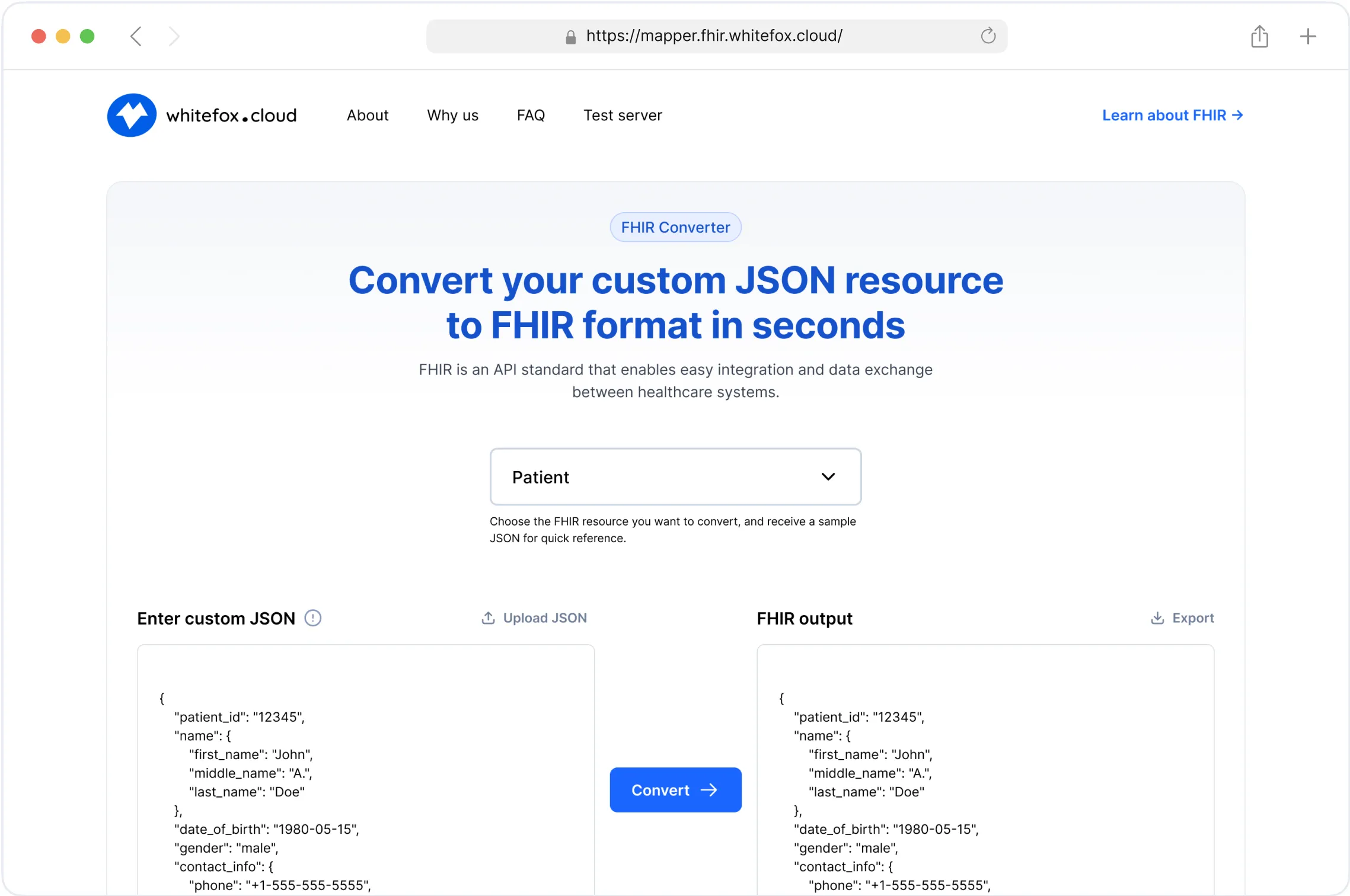
FHIR Test Server
Test, validate, and refine FHIR implementations securely online.
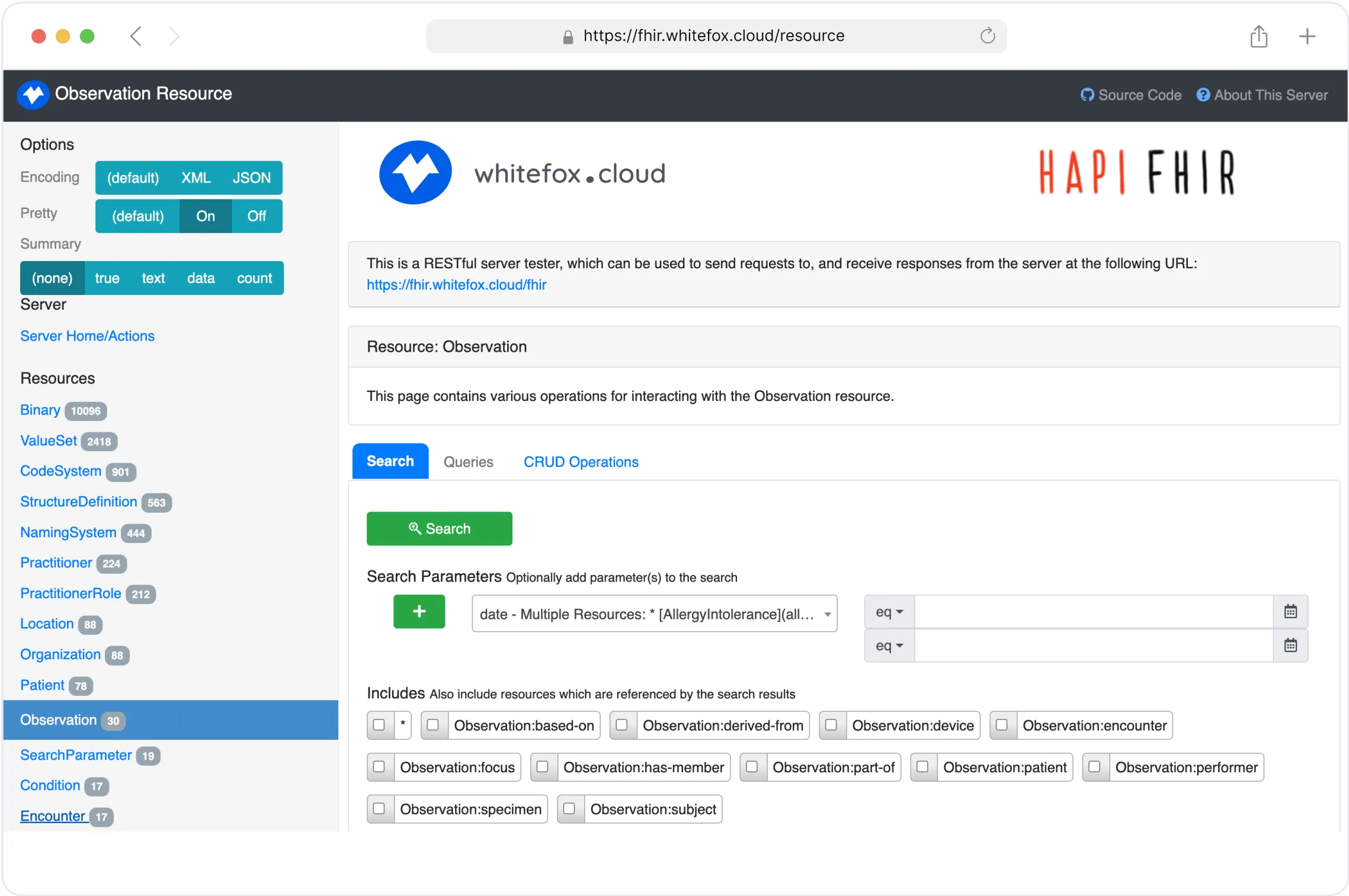
Streamline Your FHIR Implementation
We offer comprehensive FHIR services, from consultation to ongoing maintenance. Our Healthcare Software Development Services